
The more microservices you have the more you need asynchronous messaging between the microservices or scheduled jobs or background tasks.
Background tasks are good for many reasons; lifting off the heavy load from specific microservices, run stateless jobs and scheduled tasks, asynchronous messaging etc…
But failed background tasks -true to its name- can go unnoticed if you do not set up a proper monitoring or a highly available system. So you need those tasks (in short) to be fast, highly available and easy to manage.
Hence, you need a distributed, fast-paced development environment with low latency while communicating.
Therefore, I humbly suggest;
- Python, due to its simplicity.
- Celery: A distributed task queue which is actively maintained on github (with lots of contributors), fast and highly available.
- Redis: In-memory key-value store with incredibly low latency. It can be used as both (message) broker and (result) backend for Celery.
A Simple Task Queue Example
I will explain scheduled tasks and triggered tasks in this example and I’ll be using python 3.8.5 and celery==5.1.1.
Let’s consider that we have active users using our service with a paid subscription. We have to renew the expired subscriptions and send invoices to users with emails (scheduled task), send custom emails on events like registration, password recovery etc… (triggered tasks)
Scheduled Tasks
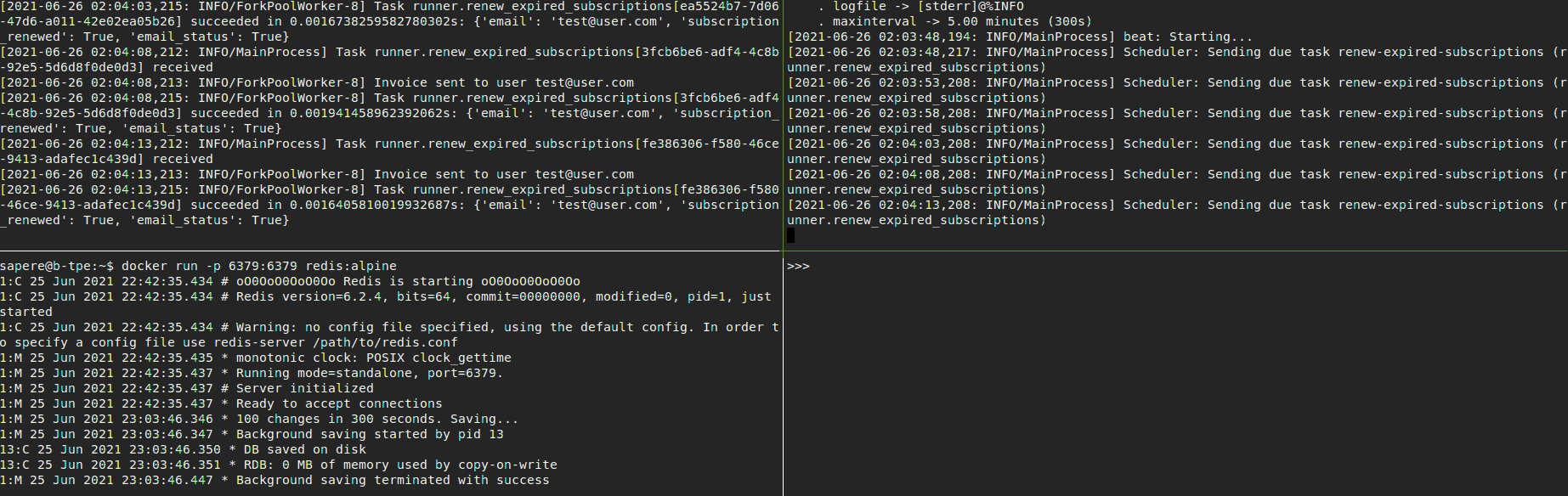
When to renew the expired subscriptions is based on the current time and the users' expiration dates stored in databases. Obviously, it would not be a good practice to check whether the users are expired or not one by one. However, we can check the database regularly for users whose expiration date has passed.
Thus, we have to set up a cron job working every X second to get the expired subscriptions , try to renew them and finally send invoice to user if the renewal was successful.
|
|
Our cron job renew_expired_subscriptions is defined and has some (dummy) functionality with the helper functions replace_fields_with_values and send_email.
Starting from the foundation; firstly we need to define our celery worker application:
|
|
'runner' is the main name for our application. See Main Names for more detailed information.
And we have some helper functions; replace_fields_with_values function replaces the placeholders in the given email template with the given values and outputs the custom email message. send_email function does as it’s name promises.
Finally you can see that we’ve also defined the cron task renew_expired_subscriptions, which has some dummy subscription renewal logic inside it. Every celery task is defined under a @app.task decorator.
We also need to define beat configuration for scheduled tasks:
|
|
This configuration object can be extended for added cron tasks. We set the crontab to 5 seconds for our subscription renewal task.
Now, we can run the workers:
|
|
Triggered Tasks
Apart from the scheduled tasks, there might also a need for triggered tasks. These tasks are triggered when an event is fired.
When the event is fired, some message (task data) is pushed to the message broker (a.k.a bus). Then the workers get the tasks in the queue from the message broker and process them.
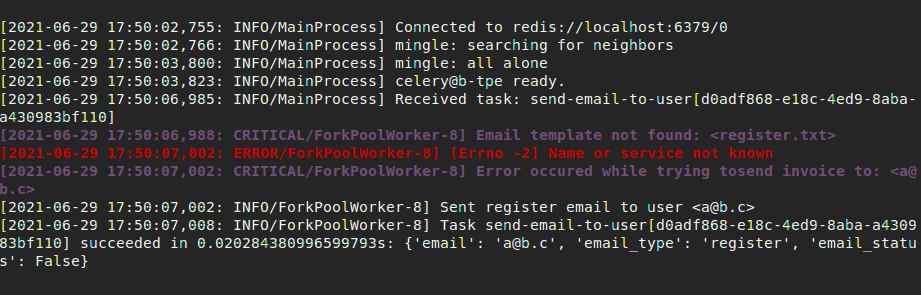
In our case, we need to send emails to users when some events occur, like registration, new subscription, password recovery and so on.
With the retry settings and a soft timeout limit, our email sending task should look something like:
|
|
To trigger this task manually, spin up your workers, a local redis and run a Python command at the project directory:
|
|
You can see the result at the worker:
Conclusion
With use of task queues, you may benefit concurrent/parallel computation, microservices with less workload, resilient workers.
Now, can you run both scheduled tasks, trigger other tasks manually at the same time and monitor your workers on the other hand? You should definitely try this out. It will give you the basic understanding of how does a task queue mechanism work.
Best Practices on Tasks Queues
- Set time limits to tasks.
CELERYD_TASK_SOFT_TIME_LIMIT - Use least arguments as possible. Stateless tasks are better.
- Don’t trust your broker for security. You have to take security seriously if you have secrets in your tasks' data.
- Be aware of the limits of your connection pool limits.
- You have to make different settings for different brokers or backends. No broker or backend is the same with others.
- Exponential retry intervals are better than linear retry intervals.
- Categorize and prioritize your queues.
- Monitor your workers and log properly.
Further Read
- Secure Celery (Celery official docs.)
- Secure Redis (Redis official docs.)
- Eviction Policy on Redis (Redis official docs.)
- Monitoring Celery Workers (Celery official docs.)
- Integrate Sentry to Celery
- Cherami: Uber Engineering’s Durable and Scalable Task Queue in Go
- Breaking out of message brokers | Snyk